![[JPA] @Modifying 벌크 연산](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbhgzIs%2FbtsIhVa2D8Y%2F3mddpPFNKXByQiRkbQaQMk%2Fimg.png)

벌크 연산이란?
벌크 연산이란 DB에서 UPDATE, DELETE 시에 대량의 데이터를 한 번에 처리하기 위한 작업이다.
JPA에서 벌크 연산이란 데이터 하나하나를 변경하는 것이 아닌, 여러 데이터에 한 번에 변경 쿼리를 날리는 것이다.
@Modifying 애너테이션이란?
@Modfying 애너테이션은 Spring Data JPA에서 데이터 변경 쿼리(INSERT, UPDATE, DELETE)를 사용할 때 사용된다. 주로 @Query 애너테이션을 사용하여 정의한 JPQL 또는 네이티브 쿼리가 INSERT, UPDATE, DELETE를 포함하는 경우 @Modifying을 함께 사용한다.
아래 코드는 오류가 발생하는 코드이다. 위에서 말했듯이 @Query를 사용하여 데이터 변경을 시도하면 @Modifying 애너태이션을 함께 사용해야 한다.
public interface NotificationRepository extends JpaRepository<Notification, Long> {
@Query("UPDATE Notification SET isRead = :readStatus WHERE isRead = :unReadStatus AND receiver.id = :userId")
void readNotificationAll(@Param("readStatus") NotificationStatus readStatus,
@Param("unReadStatus") NotificationStatus unReadStatus,
@Param("userId") Long userId);
List<Notification> findNotificationByReceiverId(Long receiverId);
}아래 예외 메시지를 보면 SELECT 쿼리를 예상했으나, UPDATE 쿼리문이 발생했다는 메시지를 보여준다.
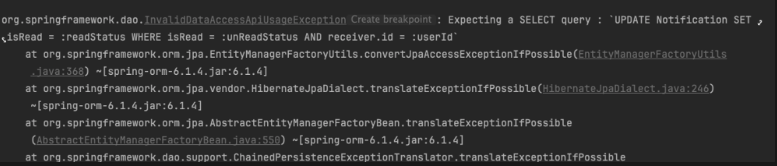
@Modifying의 문제점
- findProductById()에 의해 SELECT 문을 실행하고, 조회 결과를 영속성 컨텍스트에 저장한다.
- getName()을 호출하면 영속성 컨텍스트에 저장된 product의 name을 가져온다.
- @Query 애너테이션을 통해 벌크 연산을 수행한다.
- 다시 findProductById()를 호출하는데, 이때는 DB에서 product를 가져오는 것이 아닌 영속성 컨텍스트에서 가져온다. (product에 해당하는 ID가 영속성 컨텍스트에 저장되어 있음.)
- product의 이름을 출력한다.
@Transactional
public void changeName(Long productId) {
Product product = productRepository.findProductById(productId); // 1. 조회
System.out.println(product.getName()); // "대나무" 출력
productRepository.changeNameToBamboo(); // 2. 모든 product 이름을 Bamboo로 바꾼다
Product productAgain = productRepository.findProductById(productId); // 3. 다시 조회
System.out.println(productAgain.getName());
}
과연 5번에서 Bamboo를 출력할까 아니면 대나무를 출력할까? 2번에서 벌크 연산을 수행하여 모든 product의 이름을 Bamboo로 바꿨기 때문에 Bamboo를 출력할 것으로 예상할 수 있다. 그러나 예상과 달리 대나무를 출력한다.
@Modifying을 통해 벌크 연산을 수행하면 DB에 영향을 미치지만, 영속성 컨텍스트에는 영향을 미치지 않는다. 따라서 DB에 저장된 내용과 영속성 컨텍스트가 갖고 있는 데이터가 일치하지 않는 문제가 발생한다. 5번에서 Bamboo가 아닌 대나무가 출력된 이유는 영속성 컨텍스트에서는 여전히 대나무를 name으로 갖는 product를 저장하고 있기 때문이다.
결국 영속성 컨텍스트에 저장된 엔티티에 더티 체킹을 수행하는 것이 아닌, DB로 바로 데이터 변경 연산을 실행하기 때문이다.
@Modifying 문제 해결하기
문제를 해결하기 위해서 @Modifying에 2가지 옵션을 사용할 수 있다.
- flushAutomatically : 쿼리 실행 전 쓰기 지연 저장소의 쿼리를 데이터베이스로 flush 한다. (default = false)
- clearAutomatically : 쿼리 실행 후 영속선 컨텍스트를 clear 한다. (default = false)
@Modifying(clearAutomatically = true)
@Query("UPDATE Notification SET isRead = :readStatus WHERE isRead = :unReadStatus AND receiver.id = :userId")
void readNotificationAll(@Param("readStatus") NotificationStatus readStatus,
@Param("unReadStatus") NotificationStatus unReadStatus,
@Param("userId") Long userId);
벌크 연산을 사용하는 것과 사용하지 않는 것
1. 벌크 연산 사용하지 않기
userId를 갖는 Notification을 데이터베이스에서 모두 조회하고, 각각의 row에 대하여 알림을 읽음 처리하고 있다.
public interface NotificationRepository extends JpaRepository<Notification, Long> {
List<Notification> findNotificationByReceiverId(Long receiverId);
}// 알림 삭제
@Transactional
public void deleteNotificationAll(Long userId) {
User user = findUserById(userId); // 알림을 받은 사용자 조회
List<Notification> notifications = notificationRepository.findNotificationByReceiverId(userId);
notifications.forEach(notification -> notification.readNotification());
}
2. 벌크 연산 사용하기
@Modifying을 사용하여 userId에 해당하는 Notification에 한 번의 쿼리문으로 알림을 읽음 처리한다.
public interface NotificationRepository extends JpaRepository<Notification, Long> {
@Modifying(clearAutomatically = true)
@Query("UPDATE Notification SET isRead = :readStatus WHERE isRead = :unReadStatus AND receiver.id = :userId")
void readNotificationAll(@Param("readStatus") NotificationStatus readStatus,
@Param("unReadStatus") NotificationStatus unReadStatus,
@Param("userId") Long userId);
}// 알림 삭제
@Transactional
public void deleteNotificationAll(Long userId) {
User user = findUserById(userId); // 알림을 받은 사용자 조회
readNotificationAllByUserId(user); // 사용자가 받은 알림을 모두 읽음 처리
}
private void readNotificationAllByUserId(User user) {
notificationRepository.readNotificationAll(NotificationStatus.READ,
NotificationStatus.UNREAD, user.getId());
}
벌크 연산을 사용하지 않고 1번의 방법을 사용한다면 데이터의 건수가 많아질수록 쿼리문 또한 많이 발생한다. 만약 데이터를 변경하고자 하는 데이터가 100만 건이라면, 100만 건을 모두 조회하고 100만 건에 대해서 데이터변경 쿼리문을 발생시켜야 한다.
그러나 벌크 연산을 사용하면 100만 건의 데이터가 존재하더라도 1번의 데이터 변경 쿼리문으로 데이터를 변경할 수 있기 때문에 벌크 연산을 적용하는 것이 유리하다.
따라서 벌크 연산의 장점을 아래와 같이 정리할 수 있다.
- 벌크 연산을 사용하면 단일 쿼리로 여러 데이터를 한 번에 처리할 수 있다.
- 반대의 경우, 개별적으로 조회하고 업데이트해야 하기 때문에 많은 쿼리를 발생시킨다.
![[JPA] 양방향 참조 시에 발생하는 순환 참조 문제](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbCsbC2%2FbtsGZkwaFPU%2FZwBhkYBgbddHef7jcb7J6K%2Fimg.png)
![[JPA] OSIV(Open Session In View) 정리](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdgZ5Ad%2FbtsGsqQCle3%2FKlLQmtPeUNpft4w7PGdTt1%2Fimg.png)
![[JPA] 다른 Transaction에서 조회한 엔티티 비교](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FP3AnR%2FbtsGqMGXmJG%2F8gIwDNqBI0Gs6ipYFawMc0%2Fimg.png)
![[JPA] Spring Data JPA Repository -> 사용자 정의 Repository](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcGcduf%2FbtsGeQ9Y8X7%2Fgc8JIMeKKbV2KObIMbBIck%2Fimg.png)